
ARTIFICIAL INTELLIGENCE / MACHINE LEARNING
The accelerator is designed for generic applications to compute 3D tensor convolved by 4D tensor to increase the efficiency by 10x.
Marquee created the microarchitecture from the specification and its own RTL design and delivered the synthesizable and lint cleaned design for verification. The unit level and top level verification was done by the in house verification team
We developed the system C model for the accelerator and ran the complete set of Resnet Models
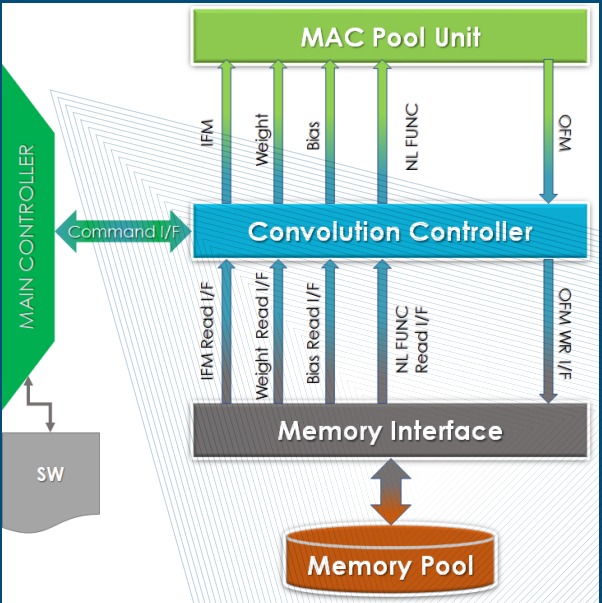
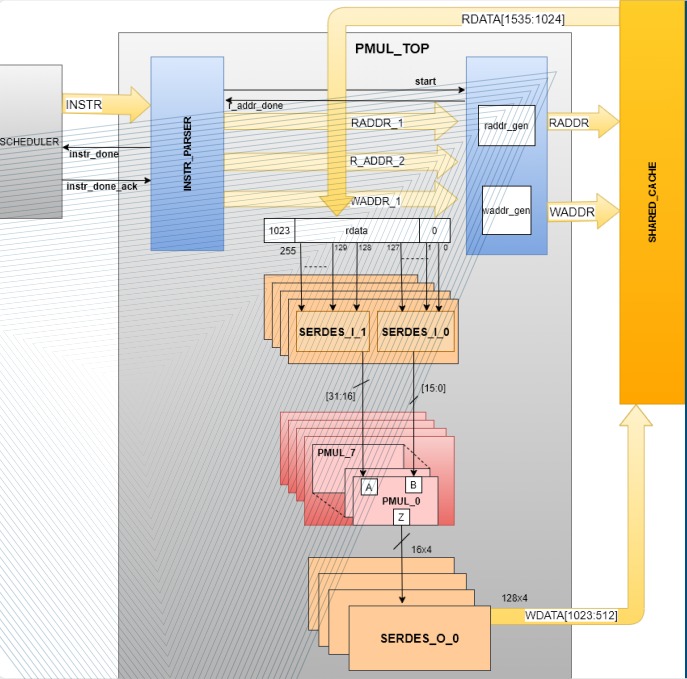
The RNN was understood with all data paths and control paths with different interfaces such as PCIe, AXI4, and DDR4. The RTL was debugged and upgraded at subsystem level to configure Processing Elements (PEs)
We developed UVM testbench architecture and developed new test cases for self checking. The design is validated using Mellanox Innova2, and U25 FPGA devices. We ran models to measure accuracy and runtime. The design was optimized to improve the E2E runtime by more than 3x at an algorithmic level and then further improved by 51x by accelerating time consuming SW process to HW using the HLS Method.